How Leveraging Near-Duplicate Identification Can Reduce Review Costs
Computers inherently create mass amounts of duplicative data. In today’s age of massive data proliferation, duplicate and near-duplicate ESI have become big contributors to excessive data populations, rising legal cost, and even a decreased confidence in data for those without access to the appropriate technology to organize and search within this data. As a result, de-duplication and near-duplication identification have become standard workflows for most eDiscovery and review teams.
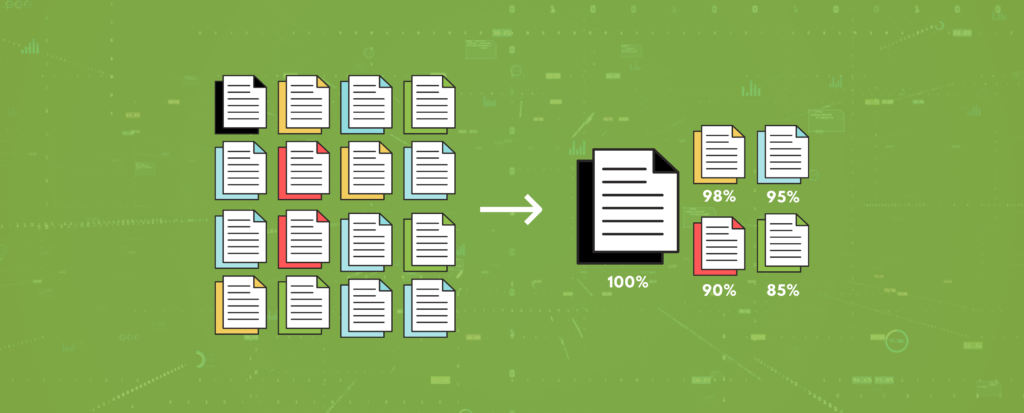
Near-Duplicate is a term commonly used describe documents that are similar but not identical to another document. These documents are nearly exact matches but tend to vary in one way or another. An example of a near-duplicate is when there are multiple revisions of a single document. Each additional copy, or revision, of the original document would be classified as a near duplicate due to the documents being textually alike but not identical.
Textual near-duplicate identification is the process in eDiscovery where all text content of a document is analyzed and compared against other documents resulting in percentage score for how similar the documents are to each other.
Near-Duplicates are not all alike, and can differ in degrees of how similar they are to the original. This can be seen where in the above example there are documents that are similar but still textually different, whereas in another example documents can be near identical but have different metadata because it was collected from a different source and/or native format. The degree to which near-duplicates are related to each other is reflected in a percentage score, with 100% being a true duplicate.
Near-Duplicates are different than true duplicates, as you can tell by the name. This is important to note because near-duplicates aren’t removed in basic de-duplication workflows. As a result, near-duplicate workflows are used along with de-duplication workflows to gain better control over the data.
Other match types include exact matches which are identical duplicates to another document, original or unique documents, and unidentified which are matches where there wasn’t enough information to determine.
Once near-duplicate documents have been identified, they can then be tagged and used in a workflow to strategically reduce your overall data population. Workflows using near-duplicate documents range from near-dupe comparison to threading and suppression of near-dupe hits for a streamlined review.
Some of the benefits of leveraging near-duplicate detection include:
- Cost savings through defensibly reducing the amount of data to be reviewed
- Easier navigation and identification of near-duplicate and related documents
- Speed up document review and increase efficiency of review teams
- Validate coding consistency
- Protect privilege across similar documents that may have been missed
Resources
[1] Relativity. (n.d.). Using near duplicate analysis in Review. Using Near Duplicate Analysis in Review. Retrieved October 21, 2021, from https://help.relativity.com/RelativityOne/Content/Relativity/Analytics/Using_near_duplicate_analysis_in_review.htm